
Multimodal vision-language models (VLMs) have made substantial progress in various tasks that require a combined understanding of visual and textual content, particularly in cultural understanding tasks, with the emergence of new cultural datasets. However, these datasets frequently fall short of providing cultural reasoning while underrepresenting many cultures. In this paper, we introduce the Seeing Culture Benchmark (SCB), focusing on cultural reasoning with a novel approach that requires VLMs to reason on culturally rich images in two stages: i) selecting the correct visual option with multiple-choice visual question answering (VQA), and ii) segmenting the relevant cultural artifact as evidence of reasoning. Visual options in the first stage are systematically organized into three types: those originating from the same country, those from different countries, or a mixed group. Notably, all options are derived from a singular category for each type. Progression to the second stage occurs only after a correct visual option is chosen. The SCB benchmark comprises 1,065 images that capture 138 cultural artifacts across five categories from seven Southeast Asia countries, whose diverse cultures are often overlooked, accompanied by 3,178 questions, of which 1,093 are unique and meticulously curated by human annotators. Our evaluation of various VLMs reveals the complexities involved in cross-modal cultural reasoning and highlights the disparity between visual reasoning and spatial grounding in culturally nuanced scenarios. The SCB serves as a crucial benchmark for identifying these shortcomings, thereby guiding future developments in the field of cultural reasoning.


The presented collection of images from our SCB encompasses visual representations of cultural concepts from seven countries, categorized across five dimensions: music, game, dance, celebration, and wedding. These images exhibit either a variety of cultural artifacts situated in diverse contexts (e.g., the depiction of the balinese legong dance showcases multiple characters, two princesses rangkesari, and one condong, with corresponding questions) or integrated distractors in addition to the primary concept (e.g., the image featuring the banduria, which displays Spanish guitars on the right side while the bandurias are positioned on the left).

Word clouds illustrating the concepts of 1,093 unique questions in SCB are categorized into five cultural themes: wedding, game, music, celebration, and dance. The variation in font size within these clouds reflects the frequency of concept occurrences relevant to each theme. A simplified form for better visualization.


The figures encompass a comprehensive analysis of the distribution of unique questions, concepts, and the average length of questions, segmented by both country and category.
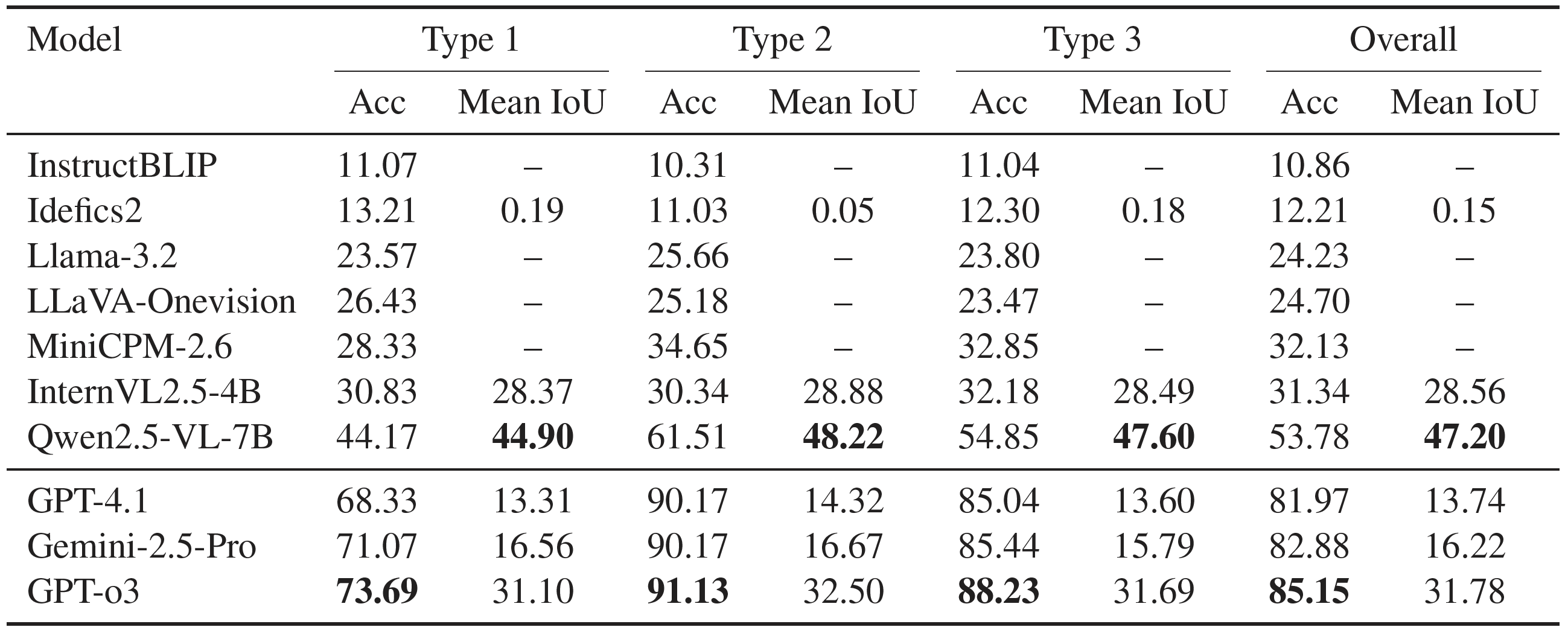
Detailed performance benchmark with several VLMs on our Visual Reasoning and Grounding task. The upper section focuses on open-source VLMs, whereas the lower section pertains to closed-source models. Type 1 is defined as within culture, Type 2 as across culture, and Type 3 represents a balanced combination of both Type 1 and Type 2.
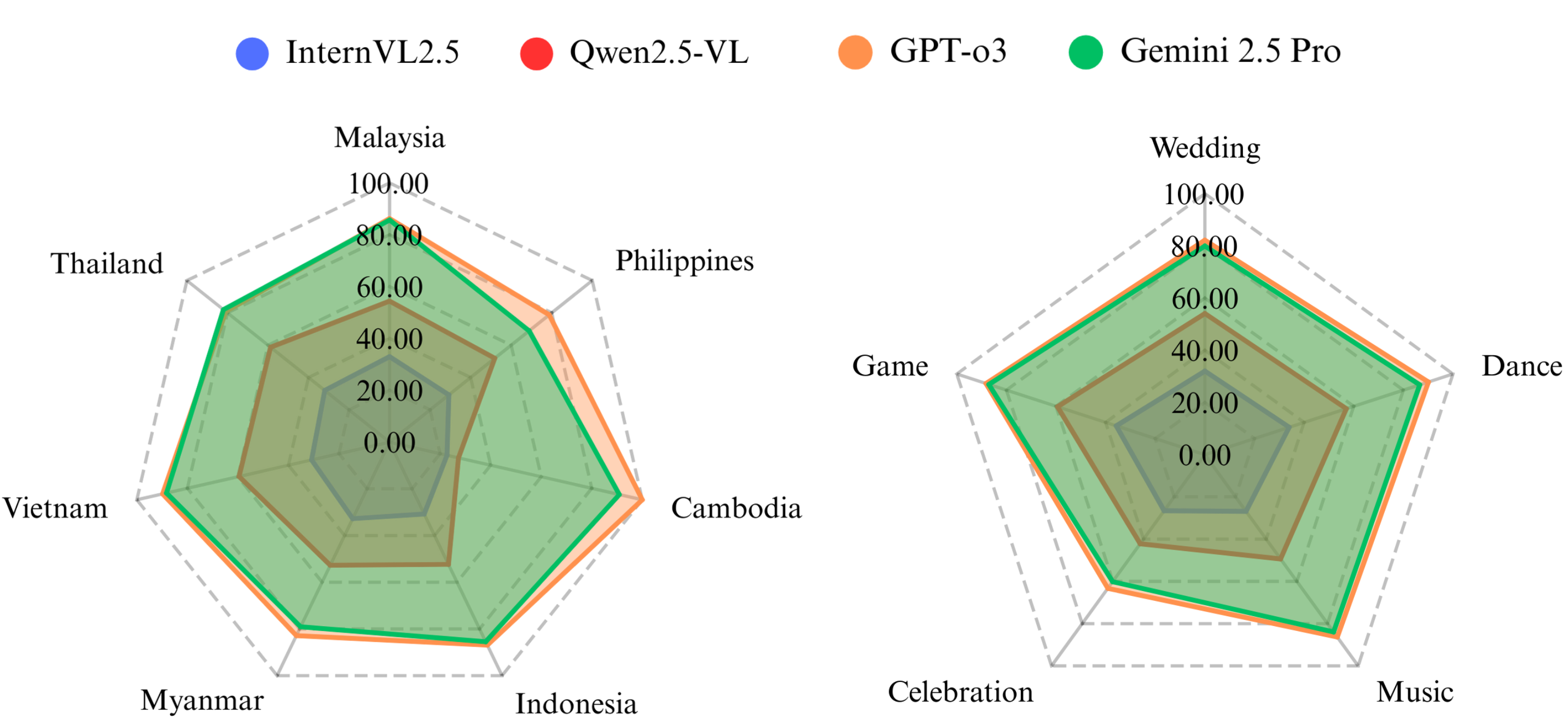
The overall multiple-choice VQA accuracy of certain VLMs across different countries and categories.

The figure presents two examples of failures for each stage. The left side illustrates an example of multiple-choice VQA, where all VLMs fail to select the correct option. Conversely, the right side pertains to the spatial grounding, for another example. Notably, this specific output is generated by GPT-o3, which is the only VLM that accurately answers the multiple-choice VQA version of this spatial grounding question. The blue character on the far left identifies the correct segment, while GPT-o3 incorrectly selects the option on the far right.
@inproceedings{satar-etal-2025-seeing,
title = "Seeing Culture: A Benchmark for Visual Reasoning and Grounding",
author = "Satar, Burak and
Ma, Zhixin and
Irawan, Patrick Amadeus and
Mulyawan, Wilfried Ariel and
Jiang, Jing and
Lim, Ee-Peng and
Ngo, Chong-Wah",
editor = "Christodoulopoulos, Christos and
Chakraborty, Tanmoy and
Rose, Carolyn and
Peng, Violet",
booktitle = "Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2025",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.emnlp-main.1131/",
pages = "22238--22254",
ISBN = "979-8-89176-332-6",
abstract = "Multimodal vision-language models (VLMs) have made substantial progress in various tasks that require a combined understanding of visual and textual content, particularly in cultural understanding tasks, with the emergence of new cultural datasets. However, these datasets frequently fall short of providing cultural reasoning while underrepresenting many cultures.In this paper, we introduce the Seeing Culture Benchmark (SCB), focusing on cultural reasoning with a novel approach that requires VLMs to reason on culturally rich images in two stages: i) selecting the correct visual option with multiple-choice visual question answering (VQA), and ii) segmenting the relevant cultural artifact as evidence of reasoning. Visual options in the first stage are systematically organized into three types: those originating from the same country, those from different countries, or a mixed group. Notably, all options are derived from a singular category for each type. Progression to the second stage occurs only after a correct visual option is chosen. The SCB benchmark comprises 1,065 images that capture 138 cultural artifacts across five categories from seven Southeast Asia countries, whose diverse cultures are often overlooked, accompanied by 3,178 questions, of which 1,093 are unique and meticulously curated by human annotators. Our evaluation of various VLMs reveals the complexities involved in cross-modal cultural reasoning and highlights the disparity between visual reasoning and spatial grounding in culturally nuanced scenarios. The SCB serves as a crucial benchmark for identifying these shortcomings, thereby guiding future developments in the field of cultural reasoning. https://github.com/buraksatar/SeeingCulture"
}